
Service Managing Digital Services
Many organisations who are delivering digital services are now trying to work out how to support and manage these services. The question is whether to retain the, often expensive, digital development teams to support and continuously improve the digital service or whether to hand over to an established service management organisation. A tough dilemma when trying to balance costs with a desire to keep the digital service evolving and fresh.My view is that we can do both simply by blending the teams. Let’s face it we all know of gung-ho developers who don’t know or care about how a solution is supported once the code is cut. However, we all know of support and maintenance developers who are uncomfortable learning new ways of doing things. The challenge is blending the team cultures into a single, long term cost effective, delivery capability.
The important point is the cross fertilisation of the teams. Having team members rotate between content creation and live support to let them understand the different skills and perspectives is critical for successful delivery.
Delivery Lifecycle Approach
To provide an end to end digital delivery lifecycle we need to blend the DevOps processes, automation and practices with robust AMS and service management practices. This blend will enable speed to live combined with the assurance of live operations. Note that there are two entry points into the model: 1. Major changes: Developed by the creation of a new delivery project 2. Minor changes: Updated and managed by the business as usual AMS teamRegardless of the team delivering, the tools, processes and lifecycle will be the same for both types of change. The AMS team will also provide an operations perspective to the project delivery sprint teams. The operations perspective is intended to bake in experience from the live support team into new projects to minimise operational support issues later in the delivery life cycle.
The approach is summarised in the following diagram with a more detailed explanation below (click image for larger).
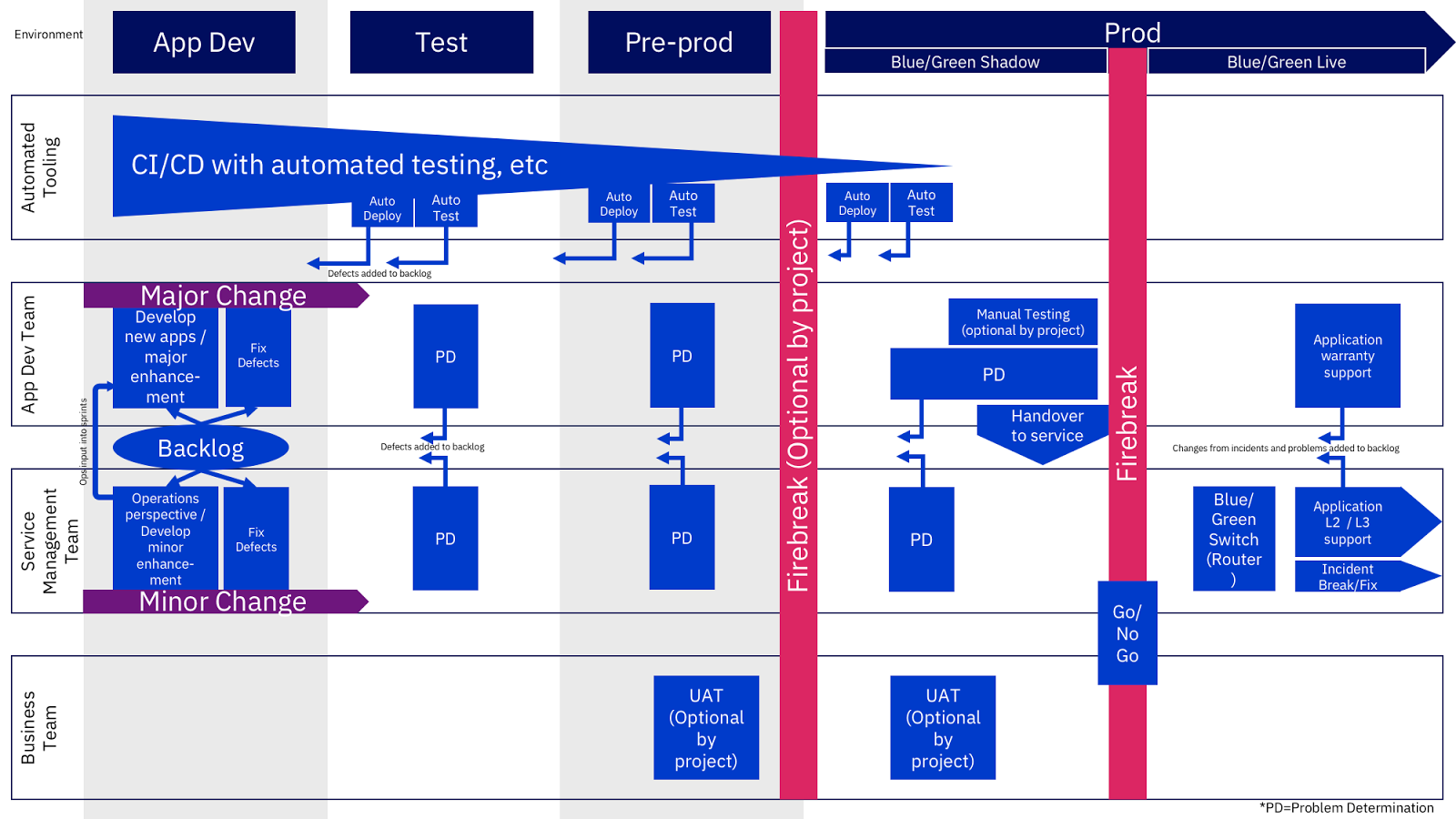
Backlog Management
The backlog is the master list of activities that need to be performed. The backlog will contain:- Stories for new functions
- Enhancement stories
- Defects raised by the automated build and test tooling
- Defects raised by manual test teams
- Enhancement stories raised by the service management team due to recorded problems or incidents
- Require the digital application development team to own; typically, new or complex stories;
- Require the application maintenance development team to own; typically, minor enhancements or service improvement stories.
| Team | Agile Style | Rationale |
|---|---|---|
| Application Development | Scrum | Working on new developments means that stories are developed are part of a delivery schedule with the emphasis of having a working solution at the end of each sprint. |
| Application Maintenance | Kanban | The maintenance team will define a work in progress (WIP) limit to determine the number of activities that they can efficiently deliver concurrently. The difference here is that items are pulled from the backlog as previous items are completed. There is no overall sprint cadence and each completed backlog item needs to result in a working production-ready solution. The advantage of Kanban in a support organisation is that activities can be delivered outside of the sprint model; which is often useful in a production scenario where patches and changes are needed within hours or days. |
Environment Flow to Live
The automation tools deploy the application into each of the path-to-live environments in turn and run the automated functional and non-functional tests appropriate for that environment. If an automated deployment or automated test fails then the following occurs:- The automation is stopped and this version of the release will not progress any further towards live;
- A ticket is automatically raised to log the error on the backlog for investigation.
By default, the automation tools deliver the release to a shadow blue/green instance in the production environment. However, depending on the scale or nature of the change then the code changes may be paused in pre-production rather than be deployed into live. This pause, or ‘firebreak’, would be enforced on a project by project basis. The firebreak may be requested if there is a risk that the new code will cause compatibility problems on production (for example, if the new code alters a database schema) or there is a need to conduct some manual testing prior to being deployed in the live environment. Manual testing will be conducted by the service management funded test team.
Once all relevant parties accept that the release paused at the pre-production firebreak is ready for live deployment then the automation tools will be manually restarted to complete the final steps of the automation.
Regardless if they had a firebreak required pause or go straight through, by default, new releases are deployed in production as a shadow blue/green deployment. The live URL to the service will still be directing web traffic to the older version of the release. The new release will be in production but will be receiving no traffic. It is possible to test the new release in the live environment by accessing it via its ‘hidden’ URL. When the new shadow release is ready be switched to become the master, there will be a live service change decision made to accept the new release into service. Following that go/no go decision we will switch the new release into live. In my view, there are no technical constraints that would stop automation all the way through from development to fully live. However, the challenges to address are:
- The risk of the automated testing scope missing problems in the automated testing that have a material impact;
- The ability for the service management teams to optimise or automate their processes to enable this deployment cadence speed.
Handover to Service Management
The DevOps ideal is “you built it, you run it” meaning that the person who wrote the code is also responsible for fixing it at all hours of the day. This is intended to make the original developer feel responsible for creating high quality, operationally supportable and reliable products.In my experience, it is important to transfer operational support responsibility away from the original developer to a wider production support team. This is because:
- A separation of duties between developer and people with access to live is important from a security and protection of service perspectives. The fewer people able to change production the safer it will be;
- Service management specialists are lower cost than digital developers;
- Relying on the original team member (or team) is a single point of failure and a scaling bottleneck in terms of retaining an understanding of how the application works;
- It results in a consistent documentation baseline that may be de-prioritised by a purely app/dev mind set.
After Live
After the new release has been deployed into production and switched to become the live release then business as usual IT service management takes over.If the release was originated from an application development team then that team will provide a period of application warranty support, or hyper care. This helps keep to the spirit of “you built it, you run it” concept but is limited in time. The service management team will be responding to incidents and investigating problems as part of business as usual. Code changes resulting from the resolution of an incident or a problem investigation will be added to the backlog as a ticket and prioritised by the product owner.
Comments
Post a Comment